

이제까지 내가 사용하지 않았던
자바의 BufferedReader와 StringBuilder, StringTokenizer 그리고 BufferedWriter에 대해
공부한다.
여기서는 BufferedReader
중요한 부분 / 정리
BufferedReader
BufferedReader는 buffer를 사용하는 입력이다.
이때 buffer는 위키백과에 따르면
컴퓨팅에서 버퍼(buffer, 문화어: 완충기억기)는 데이터를 한 곳에서 다른 한 곳으로 전송하는 동안 일시적으로 그 데이터를 보관하는 메모리의 영역이다. 버퍼링(buffering)이란 버퍼를 활용하는 방식 또는 버퍼를 채우는 동작을 말한다. 다른 말로 '큐(Queue)'라고도 표현한다.
https://ko.wikipedia.org/wiki/%EB%B2%84%ED%8D%BC_(%EC%BB%B4%ED%93%A8%ED%84%B0_%EA%B3%BC%ED%95%99)
BufferedReader는 자바 원문에 따르면
문자 입력 스트림에서 텍스트를 읽고
문자, 배열 및 행을 효율적으로 읽을 수 있도록
해당 텍스트의 데이터를 전송하는 동안
일시적으로 그 데이터를 보관하는
메모리의 영역을 채워주고
전송하는 것이다.
https://docs.oracle.com/javase/7/docs/api/java/io/BufferedReader.html
위와 같은 설명으로 보자면 Scanner와 비슷하다.
그렇다면 Scanner와 BufferedReader의 차이는 무엇일까?
조사해본 바로는 정확한 차이점은
4가지 정도가 있다.
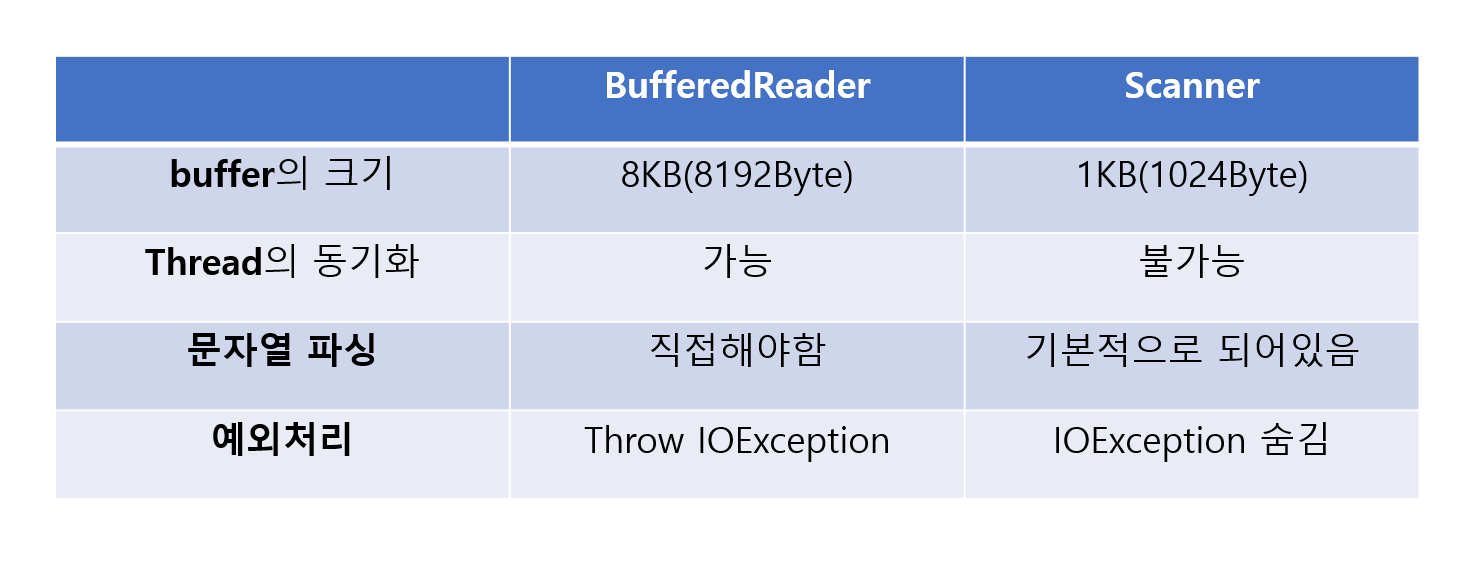
1. buffer의 크기 차이
2. Thread의 동기화 차이
3. 문자열 파싱 차이
4. 예외처리 차이
1. buffer의 크기 차이
Scanner의 크기 : 1KB(1024Byte)
BufferedReader의 크기 : 8KB(8192Byte)
BufferedReader의 buffer가 훨씬 크다.
이것때문에 BufferedReader의 속도가 빠르기에
BufferedReader를 익숙한 Scanner대신에 사용하는 것이다.
그렇다면 어째서 buffer의 크기가 속도를 정하는 것인가?
이해하기 쉽게 비유해서 말해보자면
물건을 포장해서 전달하는데
작은박스 1개에 물건을 5개씩 포장해서 전달하는 것보다
큰박스에 물건을 40개씩 포장해서 전달하는 것이
훨씬 효율적이므로 빠르다.
그러므로 버퍼의 크기 측면에서 보자면 BufferedReader가
훨씬 빠른 것은 당연할 것이다.
2. Thread의 동기화 차이
가장 먼저 Thread란 무엇인가?
스레드(thread)는 어떠한 프로그램 내에서, 특히 프로세스 내에서 실행되는 흐름의 단위를 말한다(프로세스 실행의 단위). 일반적으로 한 프로그램은 하나의 스레드를 가지고 있지만, 프로그램 환경에 따라 둘 이상의 스레드를 동시에 실행할 수 있다. 이러한 실행 방식을 멀티스레드(multithread)라고 한다.
https://ko.wikipedia.org/wiki/%EC%8A%A4%EB%A0%88%EB%93%9C_(%EC%BB%B4%ED%93%A8%ED%8C%85)
이때 프로세스는
프로세스(process)는 컴퓨터에서 연속적으로 실행되고 있는 컴퓨터 프로그램을 말한다.
https://ko.wikipedia.org/wiki/%ED%94%84%EB%A1%9C%EC%84%B8%EC%8A%A4
컴퓨터에서 프로그램이 정적에서 동적으로 변할때(프로세스 상태가 될때) 자원을 분배하는데
한 프로세스 안에서 여러개의 스레드를 작동시킬 수 있는데 그것을 멀티 스레드라고 한다.

위와 같은 상황을 멀티 스레드라고 볼 수 있는데
크롬을 실행한후 유튜브와 티스토리를 작동시킴으로써
크롬이라는 하나의 프로세스에서 여러개의 스레드를 사용함으로써
멀티스레드를 사용하고 있다고 볼 수 있다.
이때 동일한 리소스를 공유하면서 당연히 충돌이 일어날 수 있는데
이것을 방지해주는 것이 동기화이다.
이때 Mutex / Semaphore / Monitor 같은 다양한 동기화 기법이 있는데
이건 다음에 알아보도록한다.
아무튼 이러한 동기화 방식으로
BufferedReader는 동기화가 가능하여
멀티쓰레드 환경에서 안전하게 사용되고
Scanner는 동기화가 불가능하여
멀티쓰레드 환경에서는 안전하게 사용하지 못한다.
3. 문자열 파싱 차이
파싱이란 무엇인가?
컴퓨터 과학에서파싱((syntactic) parsing)은 일련의 문자열을 의미있는토큰(token)으로 분해하고 이들로 이루어진파스 트리(parse tree)를 만드는 과정을 말한다.
https://ko.wikipedia.org/wiki/%EA%B5%AC%EB%AC%B8_%EB%B6%84%EC%84%9D
가공되지 않은 데이터에서 원하는 문자열로 만들거나 빼내는 작업이다.
위와 같이 파싱을 알고서 두 차이를 보자면
BufferedReader는 데이터 타입 구분없이
문자열로만 입력을 받아내고
Scanner는 데이터 타입을 구분해서 받는데
이것을 다시 말하자면
BufferedReader는 단순히 읽어서 파싱을 알아서 해야하고
Scanner는 기본적으로 파싱을 지원해주는 것이다.
4. 예외처리 차이
이 부분은 위의 3번문자열파싱차이와 연결되는데
만약 입력값이 null이라면 문자열이 기본적으로 파싱되는
Scanner만이 null을 인식하고 대응 할 수 있고
BufferedReader는 단순히 읽어내기에
null을 인식하지 못할 수 있기 때문에
오류가 발생할 수 있어 IOException 처리를 해줘야 한다.
BufferedReader 간단 정리 끝
//참고자료는 각 부분
잘못된 정보 말씀해주시면 수정합니다. 읽어주셔서 감사합니다.
'자바 공부' 카테고리의 다른 글
| java Intellij IDEA 나의 설정 정리 (0) | 2025.02.10 |
|---|---|
| java main 메서드 분석 (2) | 2024.10.16 |
| StringTokenizer 정리 (0) | 2022.10.05 |
| StringBuilder 정리 (0) | 2022.09.29 |